pytorch的多GPU训练的两种方式 |
您所在的位置:网站首页 › pytorch 多显卡 › pytorch的多GPU训练的两种方式 |
pytorch的多GPU训练的两种方式
|
方法一:torch.nn.DataParallel
1. 原理
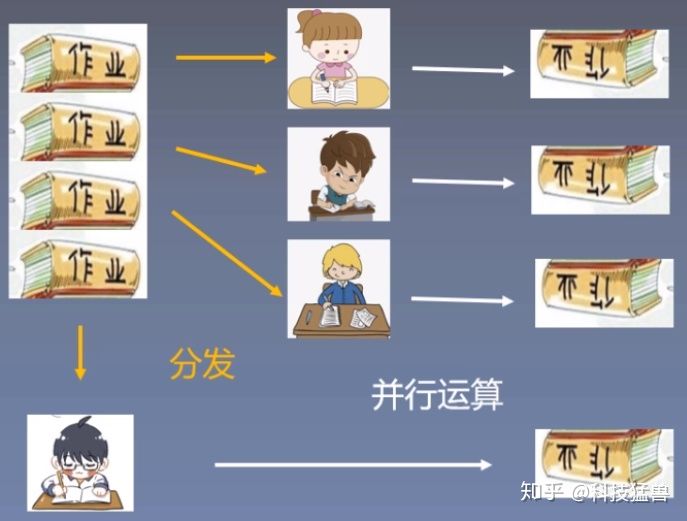
如下图所示:小朋友一个人做4份作业,假设1份需要60min,共需要240min。
这里的作业就是pytorch中要处理的data。 与此同时,他也可以先花3min把作业分配给3个同伙,大家一起60min做完。最后他再花3min把作业收起来,一共需要66min。
这个小朋友就是主GPU。他的过程是:分发 ->并行运算->结果回收。 这就是pytorch要使用的第一种并行方法:torch.nn.DataParallel 这种方法也称为单进程多GPU训练模式:DP模式,这种并行模式下并行的多卡都是由一个进程进行控制。换句话说,在进行梯度的传播时,是在主GPU上进行的。
采用torch.nn.DataParallel进行多GPU并行训练时,与其搭配的数据读取代码是:torch.utils.data.DataLoader 2. 常用的配套代码如下 train_datasets = customData(train_txt) #创建dataset train_dataloaders = torch.utils.data.DataLoader(train_datasets,opt.batch_size,num_workers=train_num_workers,shuffle=True) #创建dataloader model = efficientnet_b0(num_classes = opt.num_class) #创建model device_list = list(map(int,list(opt.device_id))) print("Using gpu"," ".join([str(v) for v in device_list])) device = device_list[0] #主GPU,也就是分发任务和结果回收的GPU,也是梯度传播更新的GPU model = torch.nn.DataParallel(model,device_ids=device_list) model.to(device) for data in train_dataloaders: model.train(True) inputs, labels = data inputs = Variable(inputs.to(device)) #将数据放到主要GPU labels = Variable(labels.to(device)) 3. 优缺点 优点:配置起来非常方便缺点:GPU负载不均衡,主GPU的负载很大,而其他GPU的负载很少 方法二:torch.distributed 1. 代码说明这个方法本来是用于多机器多卡(多节点多卡)训练的,但是也可以用于单机多卡(即将节点数设置为1)训练。 初始化的代码如下,这个一定要写在最前面。 from torch.utils.data.distributed import DistributedSampler torch.distributed.init_process_group(backend="nccl")这里给出一个简单的demo.py作为说明: import torch import torch.nn as nn from torch.autograd import Variable from torch.utils.data import Dataset, DataLoader import os from torch.utils.data.distributed import DistributedSampler # 1) 初始化 torch.distributed.init_process_group(backend="nccl") input_size = 5 output_size = 2 batch_size = 30 data_size = 90 # 2) 配置每个进程的gpu local_rank = torch.distributed.get_rank() print('local_rank',local_rank) torch.cuda.set_device(local_rank) device = torch.device("cuda", local_rank) class RandomDataset(Dataset): def __init__(self, size, length): self.len = length self.data = torch.randn(length, size).to('cuda') def __getitem__(self, index): return self.data[index] def __len__(self): return self.len dataset = RandomDataset(input_size, data_size) # 3)使用DistributedSampler rand_loader = DataLoader(dataset=dataset, batch_size=batch_size, sampler=DistributedSampler(dataset)) class Model(nn.Module): def __init__(self, input_size, output_size): super(Model, self).__init__() self.fc = nn.Linear(input_size, output_size) def forward(self, input): output = self.fc(input) print(" In Model: input size", input.size(), "output size", output.size()) return output model = Model(input_size, output_size) # 4) 封装之前要把模型移到对应的gpu model.to(device) if torch.cuda.device_count() > 1: print("Let's use", torch.cuda.device_count(), "GPUs!") # 5) 封装 model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[local_rank], output_device=local_rank) for data in rand_loader: if torch.cuda.is_available(): input_var = data else: input_var = data output = model(input_var) print("Outside: input size", input_var.size(), "output_size", output.size())(1)启动方式:在torch.distributed当中提供了一个用于启动的程序torch.distributed.launch,此帮助程序可用于为每个节点启动多个进程以进行分布式训练,它在每个训练节点上产生多个分布式训练进程。 (2)启动命令: CUDA_VISIBLE_DEVICES=1,2,3,4 python -m torch.distributed.launch --nproc_per_node=2 torch_ddp.py这里需要说明一下参数: CUDA_VISIBLE_DEVICES:设置我们可用的GPU的idtorch.distributed.launch:用于启动多节点多GPU的训练nproc_per_node:表示设置的进程数量,一般情况设置为可用的GPU数量,即有多少个可用的GPU就设置多少个进程。local rank:关于这个参数的意义,我们将在后面的情形中进行说明。(3)一些情形的说明: 情形1:直接运行上述的命令运行的结果如下: local_rank 1 local_rank 0 Let's use 4 GPUs! Let's use 4 GPUs! In Model: input size torch.Size([30, 5]) output size torch.Size([30, 2]) Outside: input size torch.Size([30, 5]) output_size torch.Size([30, 2]) In Model: input size torch.Size([15, 5]) output size torch.Size([15, 2]) Outside: input size torch.Size([15, 5]) output_size torch.Size([15, 2]) In Model: input size torch.Size([30, 5]) output size torch.Size([30, 2]) Outside: input size torch.Size([30, 5]) output_size torch.Size([30, 2]) In Model: input size torch.Size([15, 5]) output size torch.Size([15, 2]) Outside: input size torch.Size([15, 5]) output_size torch.Size([15, 2])可以看到local rank的输出为0和1,其数量与我们设置的nproc_per_node是一样的,与我们设置的可用GPU的数量是无关的。这里就要说明一下local rank的意义。 local rank:表示的是当前的进程在当前节点的编号,因为我们设置了2个进程,因此进程的编号就是0和1 在很多博客中都直接说明local_rank等于进程内的GPU编号,这种说法实际上是不准确的。这个编号并不是GPU的编号!! 在使用启动命令时,torch.distributed.launch工具会默认地根据nproc_per_node传入local_rank参数,之后再通过下面的代码可以得到local_rank. local_rank = torch.distributed.get_rank()因为是默认传入参数local_rank,所以还可以这么写,其输出与torch.distributed.get_rank()相同 import argparse parser = argparse.ArgumentParser() # 注意这个参数,必须要以这种形式指定,即使代码中不使用。因为 launch 工具默认传递该参数 parser.add_argument("--local_rank", type=int) args = parser.parse_args() local_rank = args.local_rank print('local_rank',args.local_rank) 情形2:将nproc_per_node设置为4,即将进程数设置为可用的GPU数运行结果如下: local_rank 2 local_rank 3 local_rank 1 local_rank 0 Let's use 4 GPUs! Let's use 4 GPUs! Let's use 4 GPUs! Let's use 4 GPUs! In Model: input size torch.Size([23, 5]) output size torch.Size([23, 2]) Outside: input size torch.Size([23, 5]) output_size torch.Size([23, 2]) In Model: input size torch.Size([23, 5]) output size torch.Size([23, 2]) Outside: input size torch.Size([23, 5]) output_size torch.Size([23, 2]) In Model: input size torch.Size([23, 5]) output size torch.Size([23, 2]) Outside: input size torch.Size([23, 5]) output_size torch.Size([23, 2]) In Model: input size torch.Size([23, 5]) output size torch.Size([23, 2]) Outside: input size torch.Size([23, 5]) output_size torch.Size([23, 2])可以看到,此时的local_rank共有4个,与进程数相同。并且我们设置的可用GPU的id是1,2,3,4,而local_rank的输出为0,1,2,3,可见local_rank并不是GPU的编号。 虽然在代码中模型并行的device_ids设置为local_rank,而local_rank为0,1,2,3,但是实际上还是采用可用的GPU:1,2,3,4。可以通过nvidia-smi来查看,PID为86478,86479,86480,864782。 model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[local_rank], output_device=local_rank)
此时我们再使用nvidia-smi来查看GPU的使用情况,如下。可以看到此时使用的GPU就是local rank的id。相比于情形2,我们可以总结: 当没有设置可用的GPU ID时,所采用的GPU id就等于local rank的id。本质上是将进程的编号作为GPU编号使用,因此local_rank等于进程的编号这个定义是不变的。 当设置可用的GPU ID,所采用的GPU id就等于GPU id。
输出结果如下,可以看到是报错的,因为进程数超出了可以用的GPU数量 local_rank 3 local_rank 2 local_rank 4 local_rank 1 local_rank 0 THCudaCheck FAIL file=/pytorch/torch/csrc/cuda/Module.cpp line=59 error=101 : invalid device ordinal Traceback (most recent call last): File "ddp.py", line 18, in torch.cuda.set_device(local_rank) File "/home/yckj3822/anaconda3/lib/python3.6/site-packages/torch/cuda/__init__.py", line 281, in set_device torch._C._cuda_setDevice(device) RuntimeError: cuda runtime error (101) : invalid device ordinal at /pytorch/torch/csrc/cuda/Module.cpp:59 |




【本文地址】
今日新闻 |
推荐新闻 |